Il tanto atteso modello Llama 3 di Meta è stato finalmente rilasciato nei giorni scorsi e apporta una serie di miglioramenti tecnici rispetto al precedente Llama 2. Sebbene sia un altro modello relativamente piccolo, con parametri di 8B e 80B, Llama3 mantiene l’attenzione su dati di addestramento di alta qualità e guardrail efficaci.
Meta ha utilizzato un set di dati di addestramento sette volte più grande del modello precedente (Llama 2), addestrando Llama 3 su 15 trilioni di token e sviluppando separatamente una serie di pipeline di dati, filtri e approcci basati sull’euristica per massimizzare la qualità dei dati con un numero relativamente piccolo di parametri.
Llama3 rappresenta un significativo passo avanti per i modelli di Meta, che potrà solo migliorare man mano che l’azienda perfezionerà i propri processi e rilascerà nuove iterazioni con conteggi di parametri e set di dati di addestramento più ampi. È già prevista una versione completamente multimodale, nonché una versione con conteggio di parametri 400B e supporto multilingue.
Ma cosa separa Llama 3 da modelli come GPT di OpenAI o Gemini di Google, potresti chiedere? Ecco alcuni motivi per cui il nuovo LLM di Meta è fondamentale per il futuro dell’IA.
Llama 3 è disponibile gratuitamente
Un passo unico che Meta sta compiendo nello spazio dell’intelligenza artificiale è la natura apertamente disponibile e portatile dei suoi modelli. Meta si sta unendo ad aziende come Mistral nel rilasciare il proprio modello affinché chiunque possa utilizzarlo liberamente. Ciò include una licenza illimitata per uso commerciale o di ricerca.
L’azienda è stata aperta nella sua ambizione di rilasciare pubblicamente i suoi modelli per migliorare lo sviluppo dell’intelligenza artificiale, promettendo supporto anticipato per artisti del calibro di AWS, Databricks e una serie di altre piattaforme cloud, oltre al supporto per gli sviluppatori che stanno bene. ottimizzazione dei modelli localmente.
Meta spera chiaramente di costruire un ecosistema e una catena di strumenti attorno ai suoi modelli di intelligenza artificiale e sta abbracciando a braccia aperte le grandi comunità online che stanno costruendo, formando e adattando modelli disponibili gratuitamente per tutti i tipi di applicazioni. Ciò è in netto contrasto con l’approccio più “orientato al prodotto” di aziende come OpenAI e Google. Questo potrebbe essere il tentativo di Meta di evitare la tradizionale maledizione dominante di simili disgregatori nel campo della tecnologia, che spesso investono pesantemente in prodotti pronti per il mercato solo per essere rapidamente superati e ripetuti.
Llama3 può fungere da catalizzatore per stimolare maggiore innovazione e investimenti nell’intelligenza artificiale, oltre a esternalizzare parte del carico di lavoro di Meta nella comprensione e nello sviluppo delle capacità dei propri modelli.
È possibile scaricare i pesi del modello Llama 3 direttamente dal sito web di Meta.
Limitazioni precise e serie
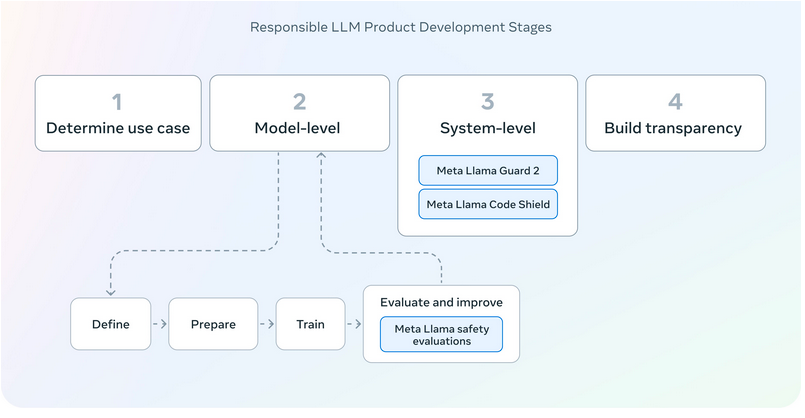
Llama 3 è stato lanciato con un approccio “a livello di sistema” sulla responsabilità dell’IA, che è qualcosa su cui altri grandi attori nello spazio dell’intelligenza artificiale sono stati notevolmente silenziosi. Parte di ciò deriva dall’approccio apertamente disponibile di Meta ai propri modelli, che potenzialmente rimuove alcuni dei guardrail che hanno consentito a artisti del calibro di OpenAI e dei modelli Gemini di Google di aggirare in qualche modo questo problema. Meta ci tiene a sottolinearne la protezione sia in fase di training che di tuning. Ciò include l’introduzione di Llama Guard 2.
Llama Guard 2 è un modello LLM separato (ironicamente addestrato su Llama 3) con parametri 8B. È progettato per fungere da protezione input-output per i modelli Llama 3, filtrando le attività in entrata in categorie di rischio e contrassegnandole come sicure o non sicure.

Meta prosegue inoltre con la suite CyberSecEval2 per la protezione da codici dannosi e attacchi di tipo “imput injection”. Inoltre, CodeShield è stato progettato per filtrare il codice non sicuro generato dal modello al momento dell’inferenza.
Più qualità e dimensioni più compatte
Meta ha adottato ancora una volta un approccio diverso rispetto ad alcuni modelli più ampi, addestrando Llama 3 nuovamente su un set di dati e un conteggio dei parametri più piccoli, ma concentrandosi su dati di altissima qualità. Questo diverso approccio ha i suoi vantaggi.
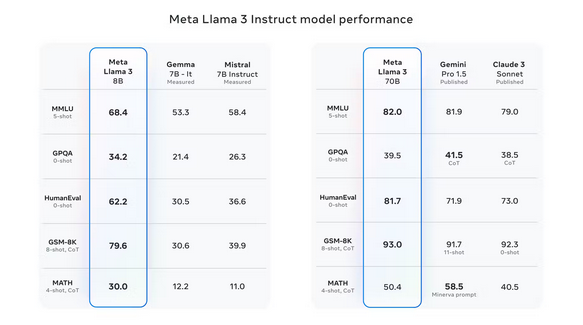
I costi di calcolo per l’addestramento del modello potrebbero essere molto inferiori (e il processo di addestramento più veloce) in questo modo, sebbene Meta ha usato comunque due cluster personalizzati da 24.000 GPU forniti da NVIDIA per addestrare Llama 3. Meta sta sostituendo l’enorme numero di parametri di LLM più grandi (si dice che GPT4 abbia più di un trilione di parametri) e concentrandosi invece su un set di dati offline di altissima qualità.
Ci sono anche altri vantaggi in questo approccio. Llama 3 è molto più semplice da eseguire su macchine locali (avrai comunque bisogno di molta potenza, anche per il modello con parametri 8B), aiutando gli sviluppatori, le startup e gli eventuali rivoluzionari dell’intelligenza artificiale a mettersi in funzione con i modelli più recenti senza la necessità per eccessivi investimenti di capitale anticipati.